
Soham Ghosh
Research Scientist · Mistral AI
I am a Research Scientist at Mistral AI working on open-source multimodal large language models such as Pixtral and Voxtral. Previously, I worked at Google Deepmind on research into improving audio-visual representation learning with language supervision. During my Masters in Carnegie Mellon University I was fortunate to work with Alexander Hauptmann on video-language grounding and Ruslan Salakhutdinov on meta reinforcement learning. I completed my undergraduate studies at Nanyang Technological University, where I was a recipient of Nanyang Scholarship and the President's Scholarship for Research and am thankful for being advised by Justin Dauwels and Adams Kong.
The best way to reach me is through ghosh.soham@gmail.com
Mission: Building artificial general intelligence that is able to perceive, understand and interact with us in natural ways and augment our own abilities.
Education
 Carnegie Mellon University (School of Computer Science)2017 – 2018M.S. · Computational Data Science (Analytics)CGPA: 4.03/4.33. Courses: Probabilistic Graphical Models, Deep RL, Large-Scale ML, Advanced Multimodal ML. Teaching Assistant for Introduction to Machine Learning and Introduction to Deep Learning.
Carnegie Mellon University (School of Computer Science)2017 – 2018M.S. · Computational Data Science (Analytics)CGPA: 4.03/4.33. Courses: Probabilistic Graphical Models, Deep RL, Large-Scale ML, Advanced Multimodal ML. Teaching Assistant for Introduction to Machine Learning and Introduction to Deep Learning. Nanyang Technological University2012 – 2016B.Eng. & M.Sc. · Engineering Science (Computer Science), Technology ManagementFirst Class Honours, Nanyang Scholarship, President’s Research Scholar. CGPA: 4.75/5.0.
Nanyang Technological University2012 – 2016B.Eng. & M.Sc. · Engineering Science (Computer Science), Technology ManagementFirst Class Honours, Nanyang Scholarship, President’s Research Scholar. CGPA: 4.75/5.0.
Publications
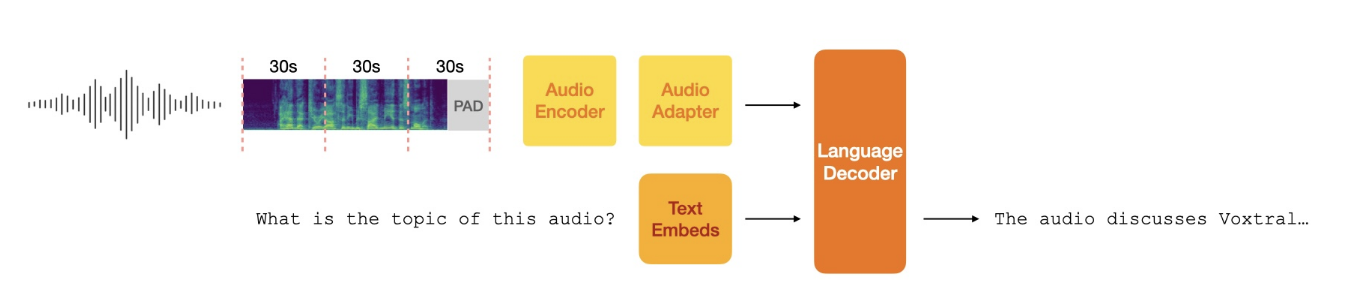
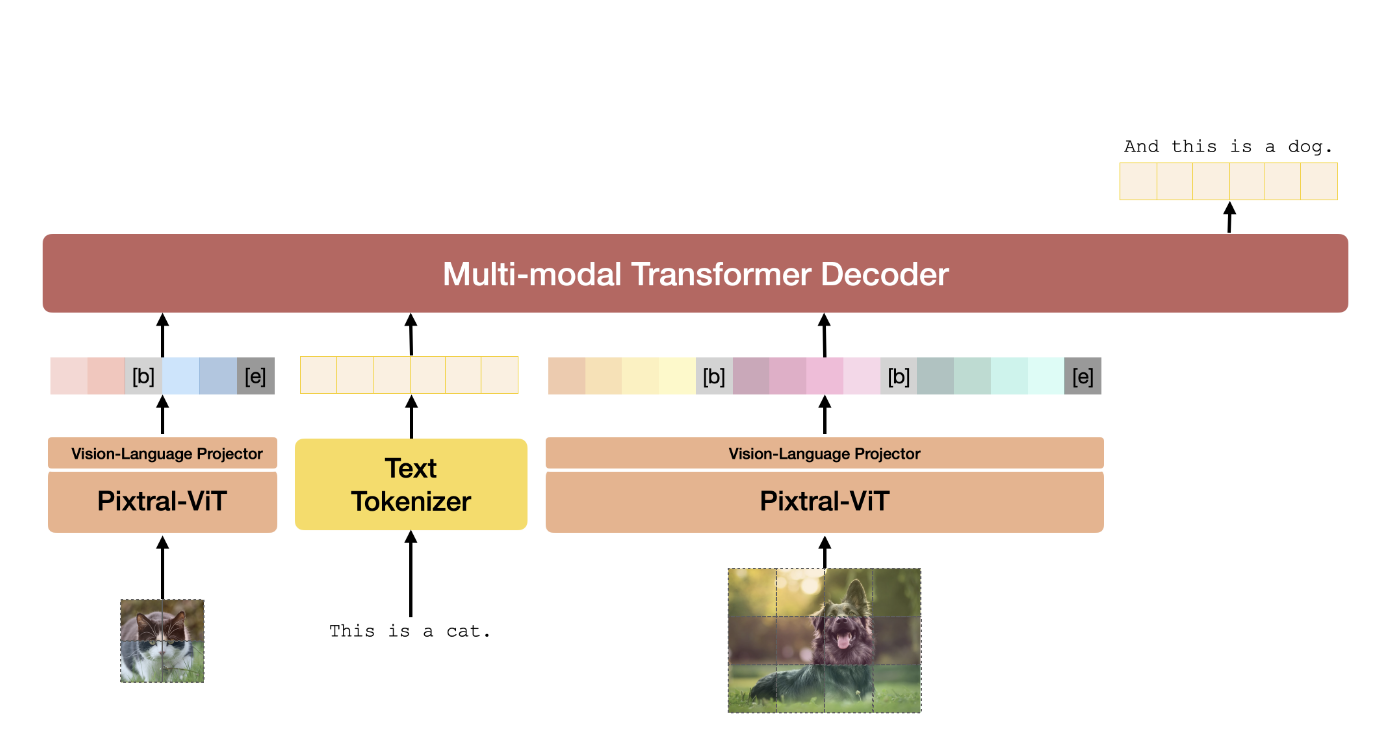
Mistral AI team
Pixtral-12B is a 12B-parameter multimodal model combining vision-language understanding with text generation, achieving leading performance on multimodal benchmarks.
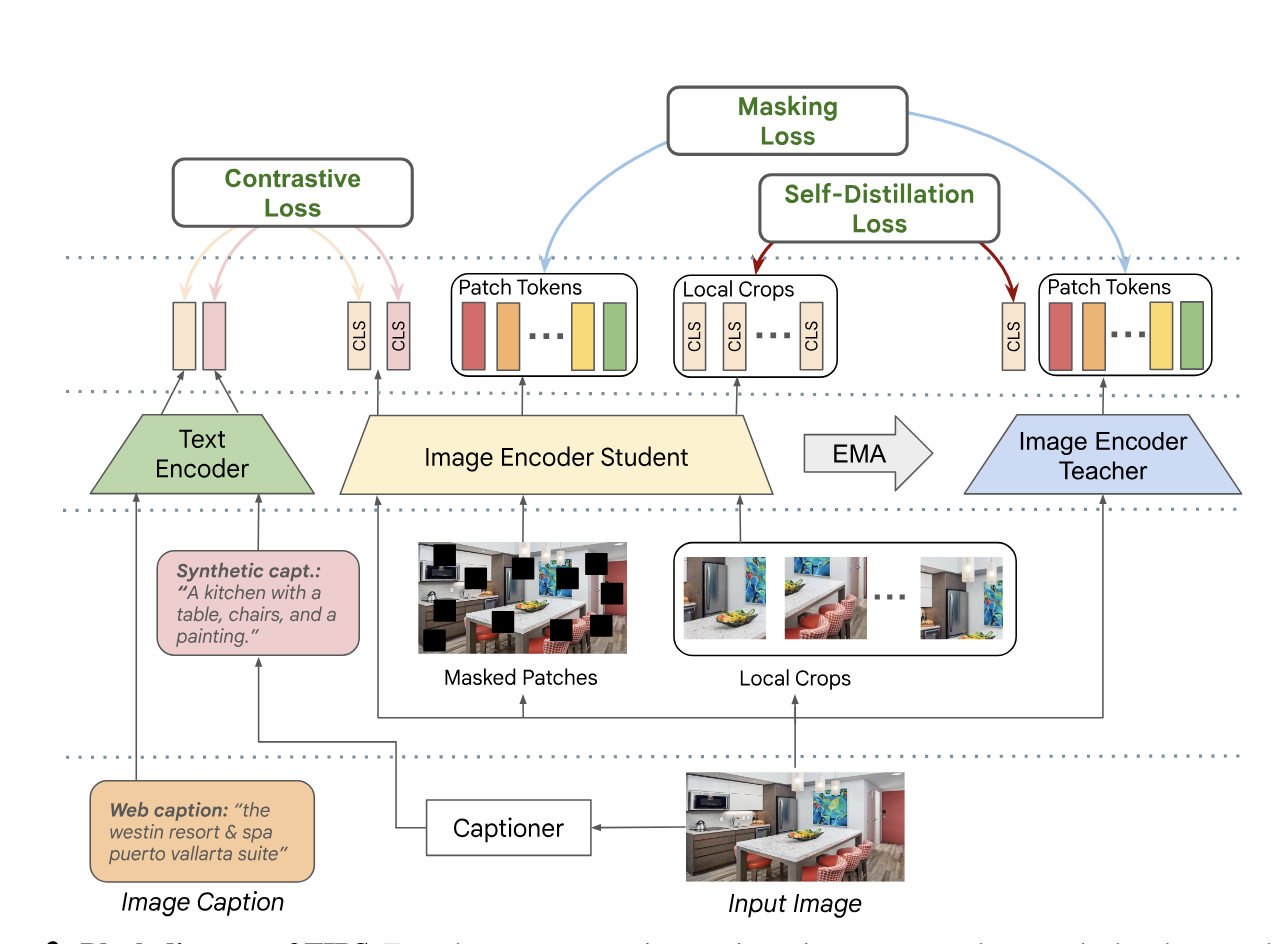
K.K. Maninis, K. Chen, S. Ghosh*, A. Karpur, K. Chen, Y. Xia, B. Cao, D. Salz, …
TIPS improves spatial reasoning in image-text models by blending contrastive learning with masked image modeling, yielding strong performance on dense and global vision tasks.
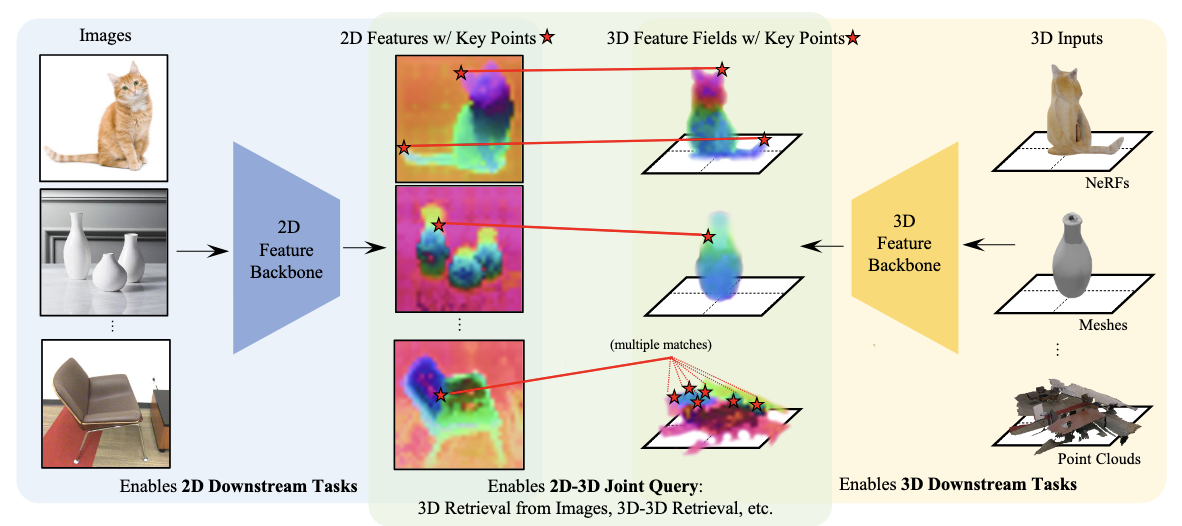
X. Zhang, Z. Wang, H. Zhou, S. Ghosh*, D. Gnanapragasam, V. Jampani, H. Su, …
ConDense jointly learns 2D and 3D representations using a NeRF-like pipeline, ensuring consistent dense and sparse features across views.
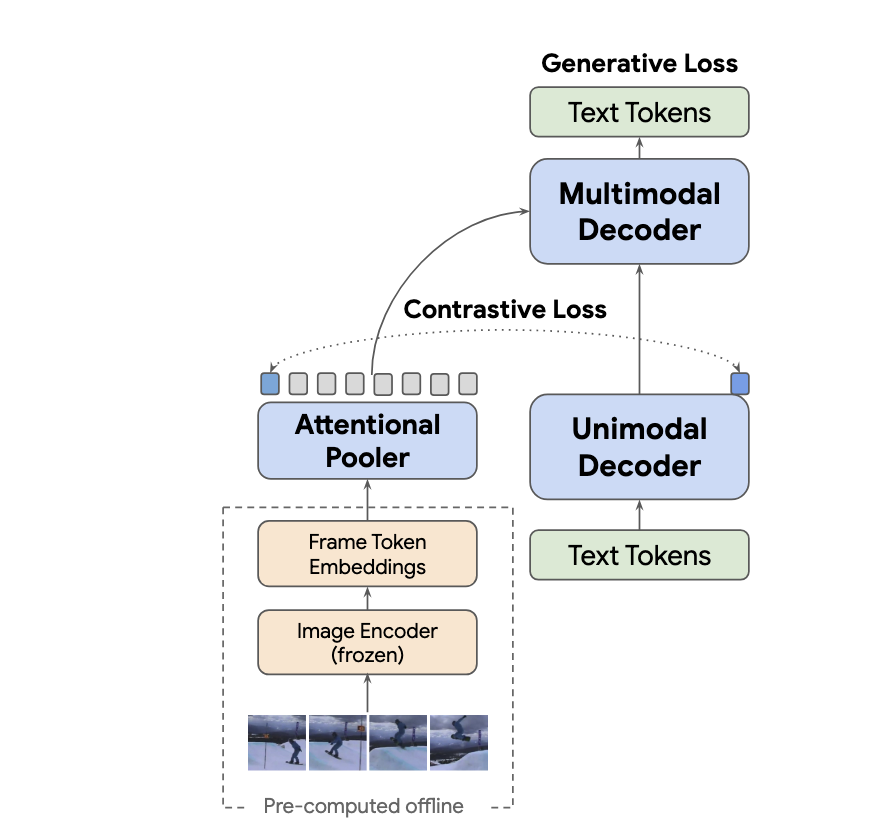
S. Yan, T. Zhu, Z. Wang, Y. Cao, M. Zhang, S. Ghosh*, Y. Wu, J. Yu
VideoCoCa adapts CoCa to video-text tasks, enabling zero-shot video classification, retrieval, and QA with minimal additional training.
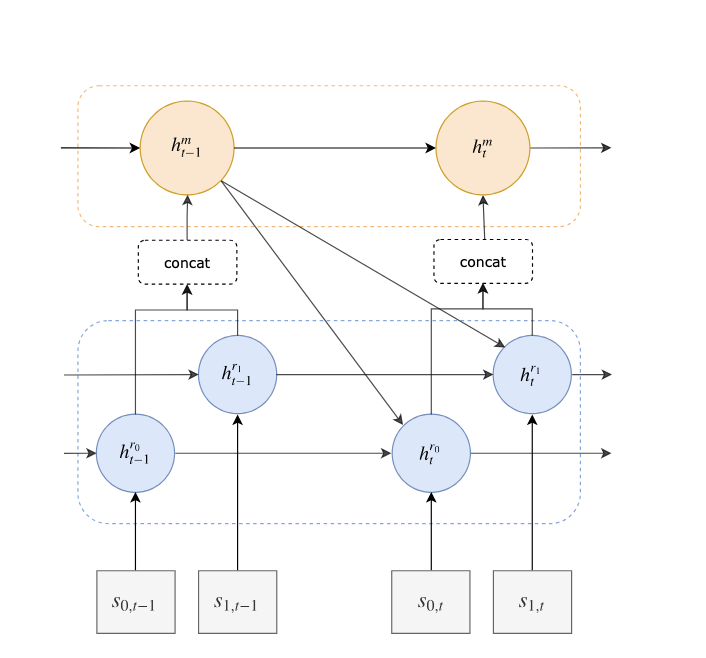
E. Parisotto, S. Ghosh*, S.B. Yalamanchi, V. Chinnaobireddy, Y. Wu, …
This work proposes a concurrent meta-RL framework that learns multiple tasks simultaneously, improving sample efficiency and generalization.

S. Ghosh*, A. Agarwal, Z. Parekh, A. Hauptmann
Presents a method for localizing video segments described by natural language, using alignment between text and temporal visual features.
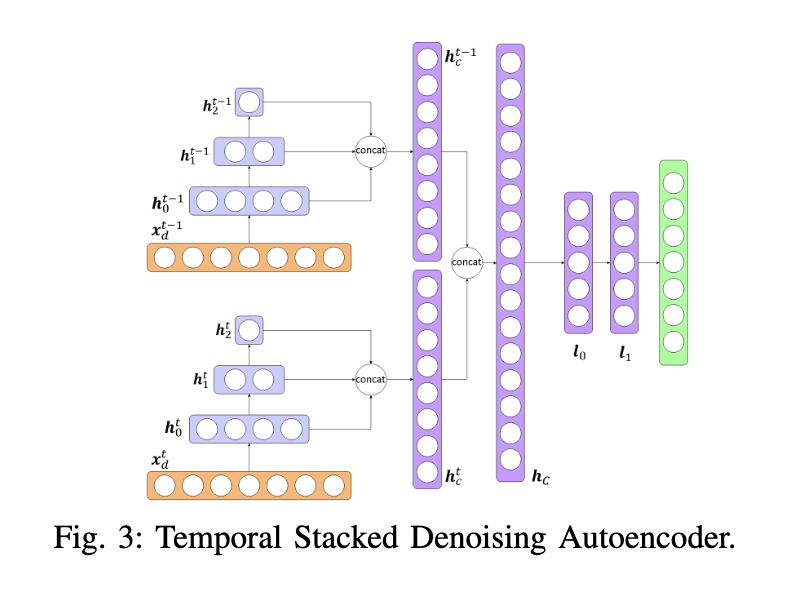
S. Ghosh*, M.T. Asif, L. Wynter
Uses denoising autoencoders to rapidly estimate real-time traffic states on large urban road networks from incomplete sensor data.
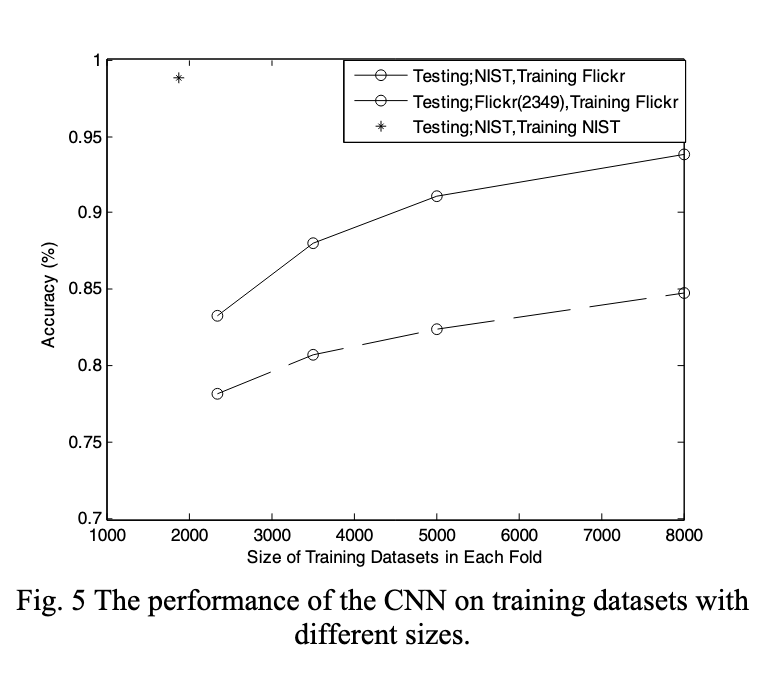
Q. Xu, S. Ghosh*, X. Xu, Y. Huang, A.W.K. Kong
Develops a CNN-based approach for tattoo detection in images, with analysis of the NIST tattoo image database.
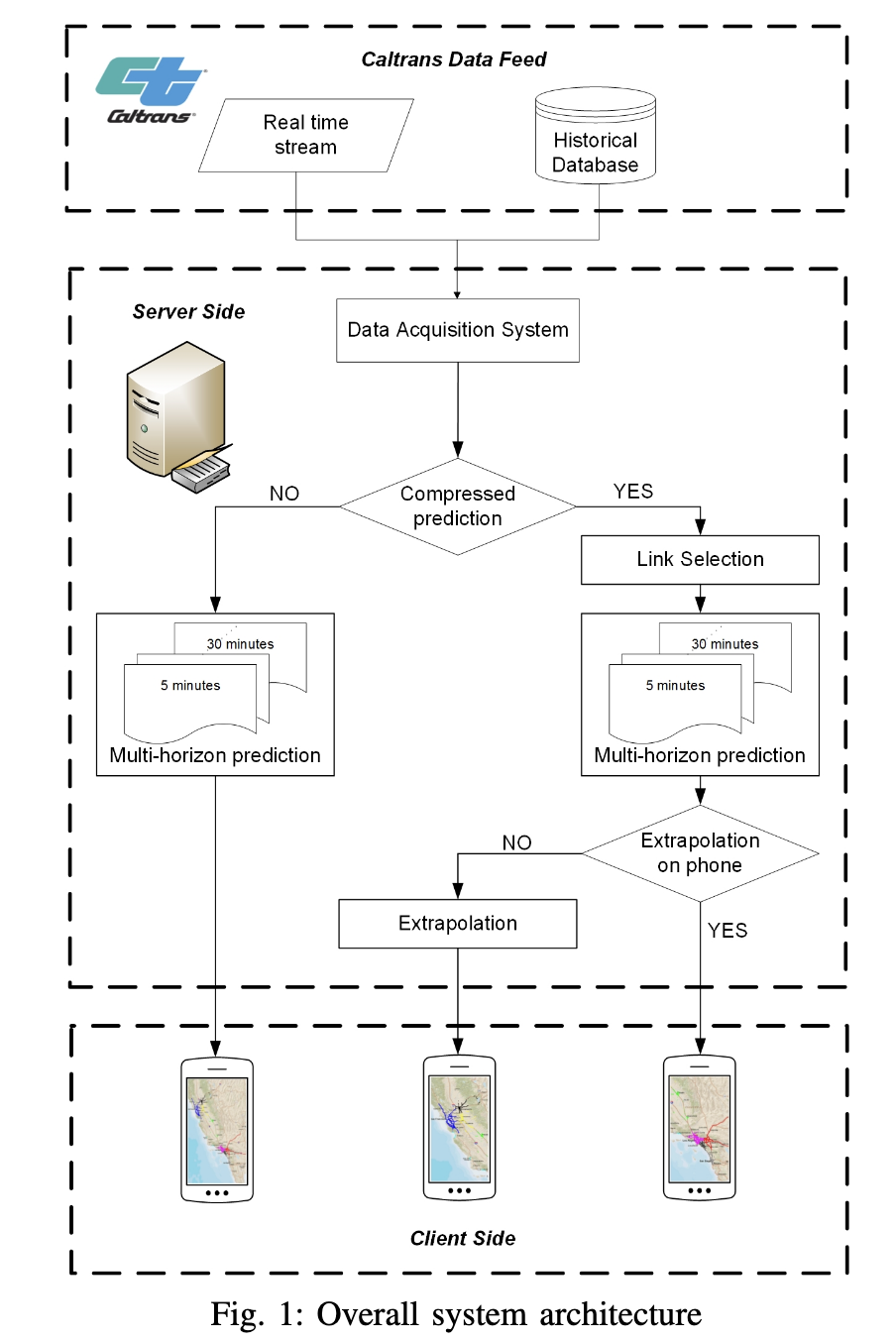
R. Ansar, P. Sarampakhul, S. Ghosh*, N. Mitrovic, M.T. Asif, J. Dauwels, …
Evaluates smartphones’ capability to perform real-time traffic prediction, highlighting feasibility and constraints for mobile deployment.